88_文本分类常见面试篇
文本分类常见面试篇
来自: AiGC面试宝典
扫码 查看更
• 文本分类常见面试篇
、文本分类任务有哪些应用场景?二、 文本分类的具体流程?• 三、 fastText的分类过程?fastText的优点?• 四、 TextCNN进行文本分类的过程?• 五、TextCNN可以调整哪些参数?• 六、文本分类任务使用的评估指标有哪些?• 致谢
来自: AiGC面试宝典
扫码 查看更
、文本分类任务有哪些应用场景?二、 文本分类的具体流程?• 三、 fastText的分类过程?fastText的优点?• 四、 TextCNN进行文本分类的过程?• 五、TextCNN可以调整哪些参数?• 六、文本分类任务使用的评估指标有哪些?• 致谢
来自: AiGC面试宝典
扫码 查看更
、抽取式摘要和生成式摘要存在哪些问题?二 、Pointer-generator network解决了什么问题?三、文本摘要有哪些应用场景?• 四、几种ROUGE指标之间的区别是什么?• 五、BLEU和ROUGE有什么不同?• 致谢
来自: AiGC面试宝典
• 1. 如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
• 2. 为什么SFT之后感觉LLM傻了?
• 3. SFT 指令微调数据 如何构建?
• 4. 领域模型Continue PreTrain 数据选取?
• 5. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能
• 6. 领域模型Continue PreTrain ,如何 让模型在预训练过程中就学习到更
• 7. 进行SFT操作的时候,基座模型选用Chat还是Base?
• 8. 领域模型微调 指令&数据输入格式 要求?
• 9. 领域模型微调 领域评测集 构建?
• 10. 领域模型词表扩增是不是有必要的?
• 11. 如何训练自己的大模型?
• 12. 训练中文大模型有啥经验?
• 13. 指令微调的好处?
• 14. 预训练和微调哪个阶段注入知识的?
• 15. 想让模型学习某个领域或行业的知识,是应该预训练还是应该微调?
• 16. 多轮对话任务如何微调模型?
• 17. 微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
• 18. 微调模型需要多大显存?
• 19. 大模型LLM进行SFT操作的时候在学习什么?
• 20. 预训练和SFT操作有什么不同
• 21. 样本量规模增大,训练出现OOM错
• 22. 大模型LLM进行SFT 如何对样本进行优化?
• 23. 模型参数迭代实验
• 24. 微调大模型的一些建议
• 25. 微调大模型时,如果 batch size 设置太小 会出现什么问题?
• 26. 微调大模型时,如果 batch size 设置太大 会出现什么问题?
• 27. 微调大模型时, batch size 如何设置问题?
• 28. 微调大模型时, 优化器如何?
• 29. 哪些因素会影响内存使用?
• 30. 进行领域大模型预训练应用哪些数据集比较好?
• 31. 用于大模型微调的数据集如何构建?
• 32. 大模型训练loss突刺原因和解决办法• 32.1 大模型训练loss突刺是什么?• 32.2 为什么大模型训练会出现loss突刺?• 32.3 大模型训练loss突刺 如何解决?
来自: AiGC面试宝典
• 1.1 什么是CRF?CRF的主要思想是什么?
• 1.2 CRF的三个基本问题是什么?
• 1.3 线性链条件随机场的参数化形式?
• 1.4 CRF的优缺点是什么?
• 1.5 HMM与CRF的区别?
• 1.6 生成模型与判别模型的区别?
宁静致远 2024年01月12日 06:45
• 1.1 Annoy• 1.1.1 Annoy 介绍• 1.1.2 Annoy 使用
• 1.2.1 Faiss 介绍• 1.2.2 Faiss 主要特性• 1.2.3 Faiss 使用
• 1.3 Milvus
• 1.4 ElasticSearch
• 1.4.1 ElasticSearch 介绍• 1.4.2 什么是倒排索引呢?• 1.4.3 ES机制
来自: AiGC面试宝典
扫码 查看更
• 方法一:在modelscope 下载你想要的模型
from modelscope.hub.snapshot_download import snapshot_download
model_dir $=$ snapshot_download(‘damo/nlp_xlmr_named-entity-recognition_vietecommerce-title’, cache_dir $\cdot=^{\prime}$ path/to/local/dir’, revision $\mathbf{\rho}_{[}=\mathbf{\rho}^{\rangle}$ v1.0.1’)
HuggingFace.co资源下载网站,为AI开发者提供模型镜像加速服务,通过下载器可以达到10M/s的下载速度,解决大模型下载时间长、经常断线、需要反复重试等问题,实现镜像加速、断点续传、无人值守下载,
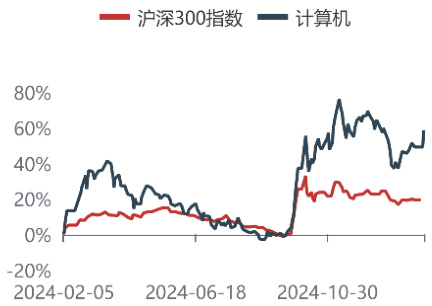
行情走势图
【平安证券】行业动态跟踪报告*计算机*AI 动态跟踪系列(三):复杂推理大模型 OpenAI o1 亮相,数学与代码能力飞跃*强于大市 20240914
【平安证券】行业动态跟踪报告*计算机*AI 动态跟踪系列(二):英伟达GTC2024AI软件与应用有哪些看点?*强于大市 20240327
【平安证券】行业动态跟踪报告*计算机*AI 动态跟踪系列(一):Duolingo4Q23业绩超预期,持续关注$\mathsf{A l}+$ 教育应用前景*强于大市 20240305
DeepSeek 发布高性价比开源模型,有望拉平模型差距、加速 AI 云与应用发展
行业研究·行业快评
互联网·互联网Ⅱ
投资评级:优于大市(维持)
证券分析师: 张伦可 0755-81982651 zhanglunke@guosen.com.cn 执证编码:S0980521120004
$\spadesuit$ 国产科技创新,DeepSeeK树立 AI性价比标杆
2025 年1月 20 日,幻方发布国产推理模型 DeepSeek-R1,在仅有极少标注数据的情况下,极大提升了模型推理能力。通过 DeepSeek-Rl 的输出,蒸馏出 32B和70B 参数级别模型在数学、代码、自然语言推理等任务对标OpenAIol-mini 的效果。性能对标头部模型的同时,DeepSeek-Rl 的服务定价为每百万 tokens 输入1元/输出 16 元,较 ol-mini 的价格(输入11元/输出88元)大幅降低。
访问官网:在浏览器输入「www.deepseek.com」 (就像打开微信一样简单)